Dynamic Memory Allocation (implicit free list)
동적 메모리 할당기의 기본 개념과 implicit free list 기반 allocator의 흐름을 정리한다.
- 런타임 (프로그램에 실행중)에 메모리를 획득할때 동적 메모리 할당기(malloc, free)를 사용하는게 편리하고 호환성이 좋음
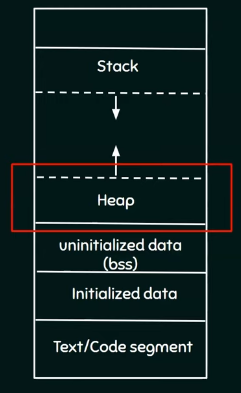
- 동적메모리 할당기는 os가 주는 힙영역에서 받아온 메모리를 관리
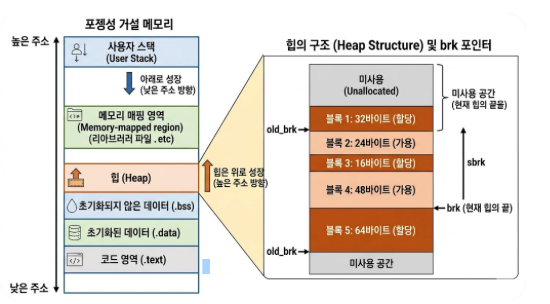
- 힙에서 메모리의 크기를 결정하고 관리하는데 brk는 위쪽 기준으로 힙의 끝이다
- 메모리를 키운다는 의미는 brk를 위쪽으로 민다는 의미 (메모리의 경계를 늘림)
[ 높은 주소 ]
↑
│
┌───────────────────┐
│ 미사용 공간 │
├───────────────────┤ ← brk (현재 힙의 끝)
│ 힙 (Heap) │
│ 할당기가 관리하는 │
│ 영역 │
├───────────────────┤
│ 데이터 영역 │
├───────────────────┤
│ 코드 영역 │
└───────────────────┘
│
↓
[ 낮은 주소 ]
메모리 구조
-
void *mem_sbrk(int incr)
static char *mem_brk; // 현재 힙의 끝(next free position)을 가리키는 포인터 void *mem_sbrk(int incr) // 힙을 incr 바이트 늘림 { char *old_brk = mem_brk; // 늘리기 전 힙 끝 주소를 저장 if ((incr < 0) || ((mem_brk + incr) > mem_max_addr)) { ... return (void *)-1; } mem_brk += incr; // 힙 끝을 incr 바이트 앞으로 이동 return (void *)old_brk; // 새로 확보된 공간의 시작 주소 반환 } //old_brk = 1000 // mem_brk = 1016 // return 1000 // 1000 ~ 1015 확보된 공간 // 유효 바이트 1015 그다음위치 1016를 가리킴 -
brk 힙영역의 메모리의 끝주소 를 늘리고 그 전의 끝 주소를 반환받는 과정
늘리기 전:
[ ... 기존 힙 ... ][mem_brk=1000]
mem_sbrk(24) 호출 후:
[ ... 기존 힙 ... ][ 새 공간 24바이트 ][mem_brk=1024]
^
old_brk=1000 반환
// ord_brk 는 새로운 공간의 시작점
- 힙의 공간이 아래와 같다 했을때
[-------------------------------------------]
이걸 할당기는 내부적으로 이렇게 쪼개 생각한다.
[블록][블록][블록][블록][블록] ...
그리고 각 블록은 상태가 다르다
- 어떤 블록은 사용 중(allocated)
- 어떤 블록은 비어 있음(free)
예를 들어
[ 사용중 32B ][ 빈공간 64B ][ 사용중 16B ][ 빈공간 128B ]
- 이렇게 본다.
- 힙 = 여러 크기의 블록들의 모음이다.
할당기는 두개의 기본 유형이 가능
- 명시적 할당기
- 프로그래머가 할당하고 해제하는걸 명시적 할당기 라고함
- 묵시적 할당기
- 프로그램이 알아서 해제 하는걸 묵시적 할당기라고함 (가비지 컬랙터)
#inclue <stdlib.h>
void *malloc(size_t size);
//malloc(size)는
// 최소 `size` 바이트 이상** 쓸 수 있는
// 연속된 메모리 블록**을 잡아주고
// 그 블록의 **시작 주소**를 포인터로 리턴한다.
- 메모리 블록의 포인터를 리턴함
그럼 처음시작 위치의 포인터와 끝위치의 포인터를 리턴해줘서 그 사이를 사용할 수 있게해주는거야?malloc은 시작 위치의 포인터 딱 하나만 리턴합니다. 끝 위치를 따로 알려주지 않는 이유는 할당기가 그 정보를 헤더(Header)에 숨겨두었기 때문입니다.- 현재위치에다가 헤더에 크기를 더하면 다음 블럭의위치를 알수 있기때문에
주소 (낮음) | +-----------+ | Header | (여기에 "크기=32"라고 적혀 있음) +-----------+ <--- malloc이 리턴하는 포인터 (p) | | | Payload | (사용자가 실제로 쓰는 24바이트 공간) | | +-----------+ | Padding | (정렬을 위한 빈 공간) +-----------+ | 주소 (높음)- malloc은 적절히 정렬된 주소를 반환해줌
- 32비트 모드에서 주소는 항상 8의배수
- 64비트 모드에서 주소는 항상 16의 배수
char *p = malloc(8);
p가 리턴하는 것
↓
주소 2000 [ ][ ][ ][ ][ ][ ][ ][ ]
↑ ↑
시작 바이트 마지막 바이트
사용 가능 범위: 2000 ~ 2007
- malloc과 free를 사용해서 블록을 할당하고 반환시키기
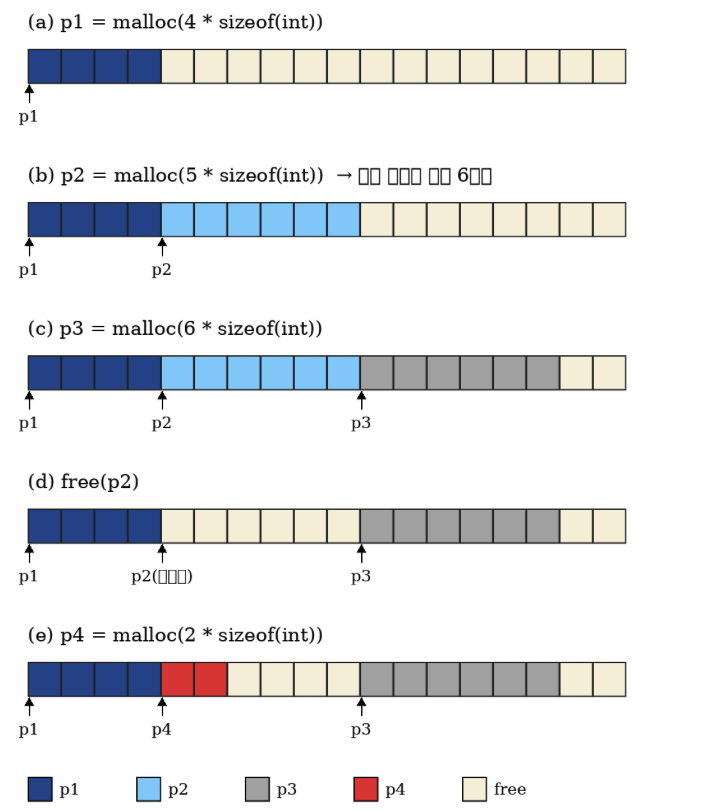
(a) 4 ints requested
[ w ][ w ][ w ][ w ]
= 4 words
= 16 bytes
-> already aligned
(b) 5 ints requested
[ w ][ w ][ w ][ w ][ w ]
= 5 words
= 20 bytes
-> not aligned to 8 bytes
add 1 more word padding:
[ w ][ w ][ w ][ w ][ w ][ pad ]
= 6 words
= 24 bytes
-> aligned
-
p1 = malloc(4 * sizeof(int))→ 처음 free 블록에서 4워드를 잘라서
p1에 할당함. -
p2 = malloc(5 * sizeof(int))→ 그 다음 남은 공간에서
p2를 할당함.→ 정렬 때문에 실제로는 6워드가 사용됨.
-
p3 = malloc(6 * sizeof(int))→ 남아 있는 free 블록에서 다시 6워드를 잘라
p3에 할당함. -
free(p2)→
p2가 쓰던 블록을 반환해서 free 블록으로 만듦. -
p4 = malloc(2 * sizeof(int))→ 새 공간을 늘리기보다, 방금 free된 p2 자리 일부를 재사용해서
p4를 할당함.
할당기 요구사항과 목표
제약사항
-
요청 순서를 마음대로 바꿀 수 없음
### 1) 임의의 요청 순서 처리하기
malloc malloc free malloc free free malloc‘아마 malloc다음에 free가 오겠지?’
‘항상 짝지어 들어오겠지?’
라는 가정을 하면 안됨
- 요청순서는 예측 불가
- 할당기는 그때그때 처리해야함
- 요청이 오면 바로 응답해야 함
- 프로그램이 malloc을 호출하면
- 요청을 모아뒀다 나중에 한꺼번에 처리하지않고 당장 적절한 블록을 찾아 응답해야함
- 힙(heap) 안에서 관리해야 함
- “할당기를 관리하려고 힙 밖에 큰 보조창고를 따로 만들지 말라”
-
정렬(alignment)을 맞춰야 함
## 4. 정렬
블록 크기를 8바이트, 16바이트의 배수로 맞추는 이유
- 데이터를 메모리에서 읽어올 때 CPU가 가장 좋아하는 ‘규격’에 맞춰 정렬함으로써 성능을 최적화하고 오류를 방지하기 위함
→
mm_malloc에서asize계산할 때 반드시 반영예:
adjustedsize=alignment맞춘실제블록크기이 계산 틀리면 전체가 무너져.
-
이미 할당된 블록은 함부로 옮기거나 수정하면 안 됨
## 5. 할당된 블록 수정 금지
→
coalesce는 free 블록끼리만 가능→ 할당된 블록은 건드리면 안 됨
즉:
[ allocated ][ free ][ free ]이면 free끼리는 합칠 수 있지만
[ allocated ][ free ][ allocated ]에서 가운데 free를 양옆과 막 합칠 수는 없어.
목표
-
처리량(throughput)높이기 vs 메모리 이용도 높이기
## 6. throughput vs utilization
이건 네 설계 선택과 직결돼.
### implicit free list
- 구현 쉬움
- 탐색 느릴 수 있음
### explicit free list
- 탐색 빨라질 수 있음
- 구현 복잡도 증가
### segregated free list
- 더 빠를 수 있음
- 설계/디버깅 더 어려움
그래서 학습 우선순위를
implicit → heap checker → realloc → explicit/segregated 비교
로 잡는 게 맞아.
단편화
메모리가 충분히 남아 있음에도 불구하고, 그 공간이 조각조각 나 있거나 규격에 맞지 않아 실제로 할당할 수 없는 ‘메모리 낭비’ 현상을 말합니다. Malloc Lab의 목표 중 하나인 이용도(Utilization) 높이기는 바로 이 단편화를 최소화하는 싸움입니다.
- 내부단편화
- 정렬(alignment)에서 블록의 최소크기, 20바이트를 할당하는 경우 8의 배수를 맞추기위해 4바이트의 크기인 1블럭을 추가하여 정렬하는 경우
- 외부단편화
- 외부 단편화는 “free 공간 총합은 충분한데, 조각조각 흩어져 있어서 큰 요청을 못 주는 현상”
### 아주 쉬운 비유
주차장 비유로 생각하면 편해.
```
[ 차 ][ 빈칸 ][ 차 ][ 빈칸 ][ 차 ][ 빈칸 ]
```
빈칸이 총 3칸이 있어도,
그게 서로 떨어져 있으면 **큰 차 1대**는 못 세울 수 있어.
즉:
- 빈 공간은 충분함
- 하지만 붙어 있지 않음
- 그래서 큰 요청을 못 받음
→외부 단편화를 줄이기 위한 방법 `coalesce`
예를 들어:
```
[ alloc ][ free 20 ][ free 28 ][ alloc ]
```
```
[ alloc ][ free 48 ][ alloc ]
```
- 이렇게 **인접한 free 블록 둘**이 있으면 합쳐셔 외부단편화를 줄임
- 이러면 큰 요청 (malloc(큰크기 요청))도 처리하기 쉬워짐
구현이슈
실용적인 할당기는 아래 4가지를 꼭 고민해야 함
- 가용 블록 구성
- 배치
- 분할
- 연결
-
초보 할당기 예시
힙의 맨 앞에서 시작하는 포인터 p 하나만 있음 malloc(size) 오면: 현재 p 위치를 주고 p를 size만큼 뒤로 민다 free(ptr) 오면: 아무것도 안 한다처음: [................................] ^ p malloc(8) [########........................] ^ p malloc(16) [########################........] ^ p free(...) 해도 그 공간을 다시 안 씀- 할당은 엄청 쉬움
- 찾을 필요도 없음
- 그냥 계속 뒤로만 감
- 처리량 은 좋을수 있지만 free를 하지않아 힙이 계속 커져 메모리 낭비가 심함
-
가용 블록 구성
어떻게 가용할 수 있는 블록을 추적할건지
## 단순한 방식 힙 전체를 처음부터 끝까지 보면서 alloc/free 표시를 확인묵시적 할당
8, 16의 배수는 마지막 3비트가 000으로 끝남 그걸이용하여
마지막 비트의 0이면 가용(사용가능) 1이면 할당(할당됨) 을 표시함
? 100001 , 100000 은 전혀 다른 주소아닌가 이렇게 표시하면 다른 배열에 접근한다는뜻아닌가
-
배치
새롭게 할당된 블록을 배치하기 위한 가용 블록을 어떻게 선택하는가?
- 빈 블록이 여러 개 있을 때
- 그중 어디에 넣을지
ex)
[ free 20 ][ alloc ][ free 40 ][ alloc ][ free 12 ]- First Fit: 힙의 시작점부터 탐색하여 크기가 맞는 첫 번째 가용 블록을 선택합니다.
- 처리량좋음
- 단편화가 많이 생겨 나중에 탐색 시간이 길어질 수 있음
- Next Fit: First Fit과 비슷하지만, 탐색을 마지막으로 할당했던 지점부터 시작합니다.
- 메모리 이용도가 제일 안좋음
- Best Fit: 모든 가용 블록을 검사하여 요청 크기와 가장 차이가 적은(딱 맞는) 블록을 선택합니다.
- 메모리 이용도 좋음
- 처리량느림
묵시적 가용 리스트 구현
-
prologue / epilogue→ 힙의 앞뒤 경계 처리를 쉽게 해주는 가짜 블록
#### prologue
- 아주 작은 가짜 할당 블록
- 힙 맨 앞에 둠
- “이전 블록 없음” 문제를 없애 줌
#### epilogue
- 힙 맨 끝에 있는 크기 0짜리 가짜 헤더
- “다음 블록 없음” 문제를 없애 줌
[ padding ][ prologue ][ ... 실제 블록들 ... ][ epilogue ]힙 전체 모양 [ pad ][ prologue hdr/ftr ][ free/alloc block ][ free/alloc block ] ... [ epilogue hdr ]coalesce입장에서는:- 맨 앞에 가도 prologue가 있으니 안전
- 맨 끝에 가도 epilogue가 있으니 안전
예외 처리를 줄이기 위한 안전 장치
-
매크로들→ header/footer/다음 블록/이전 블록을 계산하는 도구
### 블록의 정확한 메모리 모양
implicit free list의 기본 블록
[ header | payload ... | footer ]들어가있는 정보
- 이 블록의 크기
- 이 블록이 할당 상태인지 free 상태인지
### payload는 뭐냐?
- 할당된 블록이면 사용자가 쓰는 영역
- free 블록이면 일단 비어 있는 영역
-
coalesce 4가지 경우→ free된 블록을 주변 free 블록과 어떻게 합칠지
## 4. coalesce의 4가지 경우
mm_free(bp)를 하면현재 블록을 free로 바꾸고 끝이 아니야.
왼쪽/오른쪽 이웃도 free인지 보고,
가능하면 합쳐야 해.
현재 free된 블록을
C라고 하자.
### 경우 1: 이전 alloc, 다음 alloc
[ alloc ][ C free ][ alloc ]양옆이 다 사용 중이면
그냥 C만 free 상태로 둠
### 경우 2: 이전 alloc, 다음 free
[ alloc ][ C free ][ next free ]C와 next를 합침
[ alloc ][ bigger free ]
### 경우 3: 이전 free, 다음 alloc
[ prev free ][ C free ][ alloc ]prev와 C를 합침
[ bigger free ][ alloc ]
### 경우 4: 이전 free, 다음 free
[ prev free ][ C free ][ next free ]셋 다 합침
[ one big free block ] -
place / split→ 큰 free 블록을 찾았을 때 통째로 줄지, 나눌지
## 5. place와 split
find_fit으로 적당한 free 블록을 찾았다고 해보자.예:
free 블록 크기 = 40 요청 크기 = 16그럼 두 가지 선택이 있어.
### 통째로 주기
[ alloc 40 ]쉬운데 낭비가 큼
### 나눠서 주기 = split
[ alloc 16 ][ free 24 ]이게 더 좋음
### 그런데 항상 나누면 되나?
아니야.
남는 조각이 너무 작으면
그 조각은 블록으로 쓸 수 없어.
예:
free 24에 요청 16 넣고 남는 게 8 근데 최소 블록 크기가 16이면 남은 8은 쓸모 없는 조각그러면 그냥 통째로 줘야 해.
즉
place에서는 보통 이런 판단을 함:남는 크기 >= 최소 블록 크기 -> split 남는 크기 < 최소 블록 크기 -> 통째로 할당
### 왜 중요한지
이걸 잘해야:
- 내부 단편화 줄이고
- 이용도 좋아지고
- 쓸데없는 작은 조각 안 생김
-
extend_heap→ 맞는 free 블록이 없을 때 힙을 늘리는 함수
## 6. extend_heap
적당한 free 블록이 없으면
힙을 더 늘려야 해.
그때 쓰는 게
extend_heap이야.흐름은 보통 이래:
mem_sbrk(size)로 힙 늘림- 새로 받은 공간을 free 블록처럼 초기화
- 끝에 새 epilogue 헤더 설치
- 직전 블록이 free라면
coalesce
### 그림으로 보면
### 늘리기 전
[ ... 마지막 실제 블록 ... ][ epilogue ]### 힙 확장 후
[ ... 마지막 실제 블록 ... ][ 새 free 블록 ][ epilogue ]즉 epilogue가 원래 맨 끝 표시였는데,
힙을 늘리면 그 자리가 실제 free 블록의 일부가 되고
맨 끝에 새 epilogue를 다시 놓는 거야.
### 왜 바로 coalesce하냐?
만약 원래 마지막 블록도 free였다면
새로 늘린 free 블록과 붙어 있으니까 합칠 수 있어.
[ old free ][ new free ] -> [ one big free ]그래서
extend_heap은 보통 마지막에coalesce까지 같이 해.
이 5개를 mm.c 함수 흐름으로 연결하면:
mm_init
- prologue 만들기
- epilogue 만들기
- 초기 힙 준비
- 처음
extend_heap호출
extend_heap
- 힙 늘리기
- 새 free 블록 만들기
- epilogue 갱신
- coalesce
mm_malloc
- 요청 크기 정렬해서
asize계산 find_fit으로 free 블록 찾기- 있으면
place - 없으면
extend_heap후place
mm_free
- header/footer를 free로 바꾸기
coalesce
구현
-
size_t 타입을 사용하는 이유
“이 값은 일반 숫자가 아니라 메모리 크기다”라는 뜻을 코드에 분명하게 드러내기 위해
int: 일반적인 정수 (수학적 / 계산) 4바이트unsigned int: 음수를 포함하지 않는 정수 대부분의 시스템에서 여전히 4바이트(32비트)size_t: 해당 시스템의 주소 체계에 맞춰 4바이트(32), 8바이트(64비트)로 작동- 컴파일 시점(Compile-time)에 시스템 환경에 따라 4바잍, 8바이트 결정
매크로 작성
-
매크로 작성
#define WSIZE 4 // 헤더/푸터 1칸의 크기(4바이트) #define DSIZE 8 // 워드 2칸 크기(8바이트), 정렬 기준으로도 자주 사용 #define CHUNKSIZE (1 << 12) // 힙을 늘릴때 기본으로 요청하는 사이즈 2 의 12승->4096 #define MAX(x, y) ((x) > (y) ? (x) : (y)) // 둘중 더 큰 값 반환, 사용자가 요청한 크기/최소한 확보해야하는 기본 크기 중 큰값 반환 #define PACK(size, alloc) ((size) | (alloc)) // 블록크기 size와 할당 여부를 하나의 값으로 합쳐, header/footer에 저장할 값을 만든다. #define GET(p) (*(unsigned int *)(p)) // 주소 p가 가리키는 곳에 있는 4바이트 값(unsigned int 양수값)을 읽어온다. #define PUT(p, val) (*(unsigned int *)(p) = (val)) // 주소 p가 가리키는 곳에 val 값을 4바이트 정수로 저장 #define GET_SIZE(p) (GET(p) & ~0x7) // header/footer 값에서 크기 부분만 꺼내기 #define GET_ALLOC(p) (GET(p) & 0x1) //이 블록이 사용 중인지(1), 빈 블록인지(0) 확인 #define HDRP(bp) ((char *)(bp) - WSIZE) // payload 포인터 bp를 가지고 header 주소를 찾아라 #define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE) // bp가 가리키는 블록의 footer 주소 #define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp) - WSIZE))) // bp위치 + (전체크기 -4) // NEXT_BLKP(bp)는 현재 블록 크기만큼 앞으로 이동해서 다음 블록으로 감 // 1. bp는 payload라서 bp-WSIZE로 현재 header를 찾고, // 2. 거기 저장된 block size만큼 더해 다음 payload로 이동 #define PREV_BLKP(bp) ((char *)(bp) - GET_SIZE(((char *)(bp) - DSIZE))) // bp-DSIZE 위치에서 이전 block footer의 size를 읽고, // 그 크기만큼 빼서 이전 payload로 이동 static char *heap_listp; // 힙 리스트 시작점을 가리키는 전역 포인터
mm_init
- mm_init
-
전체 코드
int mm_init(void) { // if (heap_listp = mem_sbrk(4 * WSIZE) == (void *)-1) { // return -1; // } if ((heap_listp = mem_sbrk(4 * WSIZE)) == (void *)-1) { return -1; } PUT(heap_listp, 0); // 패딩넣어줌 생성 PUT(heap_listp + (1 * WSIZE), PACK(DSIZE, 1)); // 프롤로그 헤더 넣어줌 PUT(heap_listp + (2 * WSIZE), PACK(DSIZE, 1)); // 프롤로그 푸터 넣어줌 PUT(heap_listp + (3 * WSIZE), PACK(0,1)); // 에필로그 헤더 넣어줌 heap_listp += (2 * WSIZE); // 페이로드 자리 옮겨줌 프롤로그 푸터 자리로 if (extend_heap(CHUNKSIZE / WSIZE) == NULL) { // 청크 사이즈 4096로 늘리는데 null이면 리턴함 return -1; } return 0; } -
힙 공간에 초기 세팅을 만드는 함수
[ padding | prologue header | prologue footer | epilogue header ]0단계:
mem_sbrk(4 * WSIZE)WSIZE = 4라면 총16바이트, 즉 4칸을 확보처음 확보한 4워드 공간 주소 낮음 -> 높음 [ 0칸 ][ 1칸 ][ 2칸 ][ 3칸 ]- 아직은 그냥 빈 공간
1단계:
PUT(heap_listp, 0);첫 칸에 0을 씀. 이건 padding.
[ padding ][ ? ][ ? ][ ? ]- 정렬 맞추기 쉽게 하려고 두는 빈 안전칸
2단계:
PUT(heap_listp + (1 * WSIZE), PACK(DSIZE, 1));- 두 번째 칸에 prologue header를 씀
- 크기 =
DSIZE = 8 - alloc =
1즉, 크기 8짜리 할당된 블록이라는 뜻
- 크기 =
[ padding ][ prologue header: 8/1 ][ ? ][ ? ]3단계:
PUT(heap_listp + (2 * WSIZE), PACK(DSIZE, 1));세 번째 칸에 prologue footer를 씀
[ padding ][ prologue hdr: 8/1 ][ prologue ftr: 8/1 ][ ? ]- 왜 alloc로 두냐?
- coalesce할 때 맨 앞 경계를 처리하기 쉽게 하려고
4단계:
PUT(heap_listp + (3 * WSIZE), PACK(0, 1));- 네 번째 칸에 epilogue header를 씀
[ padding ][ prologue hdr: 8/1 ][ prologue ftr: 8/1 ][ epilogue hdr: 0/1 ]여기서 epilogue는:
- 크기 = 0
- alloc = 1
- 즉 힙의 끝 표시용 가짜 헤더
5단계:
heap_listp += (2 * WSIZE);현재
heap_listp는 원래 맨 처음, 즉 padding 위치를 가리키고 있었음.처음 heap_listp | v [ padding ][ prologue hdr ][ prologue ftr ][ epilogue hdr ]그런데
+ 2 * WSIZE를 하면 2칸 앞으로 이동하니까:이동 후 heap_listp | v [ padding ][ prologue hdr ][ prologue ftr ][ epilogue hdr ]즉
heap_listp가 prologue의 “payload 자리처럼 취급되는 위치” 를 가리키게 됨이걸 그림으로 더 정확히 말하면:
prologue 블록을 일반 블록처럼 생각하면 [ header ][ footer ] ^ heap_listp- 프로logue는 실제 payload가 없지만,
- 코드에서 블록 포인터(
bp)를 다루는 규칙과 맞추려고 이렇게 잡음 - 이게 중요한 이유는 나중에
HDRP(heap_listp),NEXT_BLKP(heap_listp)같은 매크로가 일관되게 동작되기 위해
초기 힙 뼈대 주소 낮음 -------------------------------------------------> 높음 [ padding: 0 ] [ prologue header: PACK(8,1) ] [ prologue footer: PACK(8,1) ] <- heap_listp가 이 근처(프로로그 payload 자리 개념) [ epilogue header: PACK(0,1) ]6단계:
extend_heap(CHUNKSIZE / WSIZE)- 이제 진짜 쓸 free block을 만들러 감
extend_heap이 힙을 늘리면 기존 epilogue 자리가 밀리고,- 그 자리에 새 free block이 생기고,
- 맨 끝에 새 epilogue가 다시 놓여.
extend_heap 후 [ pad ][ prologue ][ 첫 free block ................. ][ epilogue ]조금 더 자세히 보면:
[ padding ] [ prologue hdr: 8/1 ] [ prologue ftr: 8/1 ] [ free hdr: big/0 ] [ free payload ................. ] // 큰 free 블록 하나”를 추가 [ free ftr: big/0 ] [ epilogue hdr: 0/1 ]- 큰 free 블록 하나”를 추가
- 이제부터 allocator는 이 첫 free block을 가지고
mm_malloc요청을 처리할 수 있게 됌 → free블록에서 필요한만큼 뗴어 할당블록을 만듬→남은 부분이 크면 split해서 나머지를 free 블록으로 남김
-
extend_heap
- extend_heap
extend_heap는 “힙을 더 늘리고, 그 새 공간을 큰 free 블록 1개로 등록한 뒤, 맨 끝 epilogue를 다시 세팅하고, 필요하면 앞 free 블록과 합치는 함수
[1] 한줄 요약
맞아,
mem_sbrk(size)는 old epilogue의 “다음 자리”부터 새 공간을 줘. 그런데bp는 payload 기준 포인터라서,HDRP(bp)를 하면 한 칸 왼쪽인 old epilogue 자리를 새 free header로 덮어쓰게 되는 거야.[2] 핵심 개념 정리
mem_sbrk(size)가 주는 시작점 = old epilogue "다음" HDRP(bp) = bp의 한 칸 왼쪽 그래서 HDRP(bp)가 old epilogue 위치를 가리킴mm_init (1~5단계) → extend_heap
초기 상태 [ padding | P-HDR | P-FTR | E-HDR ] ^ old epilogue이때 mem_brk는 epilogue "뒤"에 있음 [ padding | P-HDR | P-FTR | E-HDR ] [ mem_brk ]mem_sbrk(size) 직후 [ padding | P-HDR | P-FTR | E-HDR | 새 공간 ] ^ bp- bp는 old epiloge자리가 아니라
- old epilogue “다음 칸”을 가리킴
- 그런데 bp는 “블록의 payload 포인터”처럼 쓰는 포인터라서
- HDRP(bp) = bp보다 한 칸 왼쪽
HDRP(bp)를 찍어보면 [ padding | P-HDR | P-FTR | E-HDR | 새 공간 ] ^ HDRP(bp) ^ bp즉, HDRP(bp)가 old epilogue 자리를 가리키니까 PUT(HDRP(bp), PACK(size, 0)); 를 하면 old epilogue가 새 free header로 바뀜- 즉 HDRP(bp)가 old epiologue 자리를 가리키니까
- PUT (HDRP(bp), PACK(size, 0));
- 을 하면 old epilogue가 새 free header로 바뀜
1) PUT(HDRP(bp), PACK(size, 0)) 후 [ padding | P-HDR | P-FTR | FREE-HDR | 새 공간 ] ^ bp2) PUT(FTRP(bp), PACK(size, 0)) 후 [ padding | P-HDR | P-FTR | FREE-HDR | free payload ... | FREE-FTR ] ^ bp3) PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)) 후 [ padding | P-HDR | P-FTR | FREE-HDR | free payload ... | FREE-FTR | E-HDR ] -
coalesce
case 1:
이전 alloc / 다음 alloc[ alloc ][ current free ][ alloc ] ^ bpif (prev_alloc&&next_alloc) return bp;- 아무것도 안 함
case 2:
이전 alloc / 다음 free[ alloc ][ current free ][ next free ] ^ bpsize += GET_SIZE(HDRP(NEXT_BLKP(bp))); PUT(HDRP(bp), PACK(size, 0)); PUT(FTRP(bp), PACK(size, 0));합치기 전 [ current free: 16 ][ next free: 24 ] 합치기 후 [ free: 40 ] ^ bp 유지case 3:
이전 free / 다음 alloc[ prev free ][ current free ][ alloc ] ^ bpsize += GET_SIZE(HDRP(PREV_BLKP(bp))); PUT(FTRP(bp), PACK(size, 0)); PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0)); bp = PREV_BLKP(bp);합치기 전 [ prev free: 24 ][ current free: 16 ] 합치기 후 [ free: 40 ] ^ bp 이동 (prev 쪽)case 4:
이전 free / 다음 free[ prev free ][ current free ][ next free ] ^ bpsize += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(HDRP(NEXT_BLKP(bp))); PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0)); PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0)); bp = PREV_BLKP(bp);합치기 전 [ prev:24 ][ current:16 ][ next:32 ] 합치기 후 [ free:72 ] ^ bp 이동 (prev 쪽)
mm_malloc
-
mm_malloc
1. 사용자 요청 size 받음 2. 실제 블록 크기 asize로 바꿈 3. 힙 안 free block 찾음 4. 있으면 거기에 배치 5. 없으면 힙 늘리고 거기에 배치 6. bp 반환0단계 : 변수 선언
void *mm_malloc(size_ size) // 사용자가 요청한 크기 { size_t asize; // 실제로 필요한 블록크기 size_t extendsize; // 힙을 늘릴 때 얼마만큼 늘릴지, 힙 확장 크기 char* bp; / 찾거나 새로 만든 블록의 payload 시작 주소, 현재 사용할 블록 포인터 ...1단계:
size == 0처리if (size == 0) { // 만약 사이즈(요청한크기)가 0이면 NULL반환 return NULL; }2단계 :
asize계산if (size <= DSIZE) { // size(요청크기)가 8바이트보다 작으면 기본 최소 사이즈 반환 asize = 2 * DSIZE; // 실제 필요한 블록크기를 16 최소 크기로 설정 } else { asize = DSIZE * ((size + (DSIZE) + (DSIZE - 1)) / DSIZE); }-
2단계 : asize 계산 alignment 올림용 보정 식
### 헤더와 푸터의 진짜 크기
- Header: 4바이트 (WSIZE)
- Footer: 4바이트 (WSIZE)
- payload : 8바이트
- 합계 (Overhead): 8바이트 (DSIZE)
왜 7(DSIZE - 1)을 더하나요?
- 이게 바로 이 수식의 핵심인 “올림(Rounding up)” 테크닉.
- 7바이트짜리 푸터가 있는 게 아니라, 주소를 8의 배수로 딱 맞춰주기 위한 보정치
- 정수 나눗셈의 특징을 이용한 수학적 공식,
- 어떤 수 X K의 배수로 올림하고 싶을 때 쓰는 공식은 다음과 같음
여기서 우리 상황을 대입해 보면:
- X = size + DSIZE (사용자 요청 크기 + 헤더/푸터 8바이트)
- K = DSIZE (8바이트 정렬 기준)
- 즉, 7(DSIZE-1) 은 푸터의 크기가 아니라, 너 혹시 8의 배수에서 조금이라도 넘어가면 다음 8의 배수로 점프해!”라고 밀어주는 힘
payload size + overhead(header/footer) + alignment 올림용 보정 ---------------------------------------------------------------------------- 전체 뜻: header/footer 포함한 뒤 8바이트 배수로 올림한 실제 블록 크기/ DSIZE- 8바이트 단위로 몇 덩어리인지 계산
* DSIZE- 다시 8바이트 배수 크기로 만듦
-
예시 size = 9, size = 20
### 예시 1: size = 9
가정:
DSIZE = 8asize = 8 * ((9 + 8 + 7) / 8) = 8 * (24 / 8) = 24즉 9바이트 요청이지만 실제 블록은 24바이트
### 예시 2: size = 20
asize = 8 * ((20 + 8 + 7) / 8) = 8 * (35 / 8) = 8 * 4 = 32즉 20바이트 요청 → 실제 블록 크기 32
##
3단계:
find_fit(asize)// 현재 힙안에 있는 free bloock들중 NULL아닌, free가 있으면 place하고 return bp 해라 if ((bp = find_fit(asize)) != NULL) { place(bp, asize); return bp; }왜 바로
return bp하냐?- 이미 들어갈 자리를 찾았고,
- 거기에 배치까지 끝났으니까
- 사용자에게 그 블록 주소를 주면 됨
4단계 : 못 찾았으면 힙 확장 크기 결정
extendsize = MAX(asize, CHUNKSIZE);- extendsize = asize와 CHUNKSIZE 중 더 큰 값
- 요청 블록이 작으면
→ 굳이 조금만 늘리지 말고
CHUNKSIZE만큼 크게 늘려서 future malloc 대비 - 요청 블록이 엄청 크면
→
CHUNKSIZE로는 부족할 수 있으니asize만큼은 늘려야 함
5단계:
extend_heapif ((bp=extend_heap(extendsize/WSIZE)) == NULL) { return NULL; } ------------------------------------------------------------------------------- 힙 확장 후 새 free block 얻기 실패하면 NULL (힙을 더 늘릴 공간이 없는경우)- 기존 free block으로는 못 찾았으니까
- 힙을 더 늘려서 새 free block을 만들자.
extend_heap는 words 단위로 받으니까extendsize / WSIZE로 바꿔서 넘김
6단계: 새 free block에 배치
place(bp,asize); returnbp;###
-
place
-
place
#### 0. 함수가 호출되는 시점
mm_malloc -> find_fit(asize) // 들어갈 free block 찾기 -> place(bp, asize) // 실제 배치place는 찾은 뒤에 실행되는 함수- 찾는 건
find_fit, 실제로 넣는 건place.
#### 1.
csize에 의미size_t csize = GET_SIZE(HDRP(bp));bp가 가리키는 free block의 전체 크기- ex) free block 이 40 바이트 → csize = 40
#### 2. 핵심분기 : 남는 공간이 충분한가?
if ((csize - asize) >= (2 * DSIZE)) //전체크기 - 요청크기 >= 최소블럭크기2 * DSIZE는 보통 최소 블록 크기- 는 조각이 16바이트 이상이면 새 free block으로 남김
#### 3. 분할하는 경우
if ((csize - asize) >= (2 * DSIZE)) { PUT(HDRP(bp), PACK(asize, 1)); PUT(FTRP(bp), PACK(asize, 1)); bp = NEXT_BLKP(bp); PUT(HDRP(bp), PACK(csize - asize, 0)); PUT(FTRP(bp), PACK(csize - asize, 0)); }- 3-1. 앞부분을 alloc 블록으로 만든다
- 현재 블록의 앞부분 크기를
asize로 정하고 - alloc bit를 1로 해서
- 이제 이 블록은 할당됨 이라고 표시
ex)
원래 [ free block 40 ] 앞부분 alloc 처리 후 [ alloc 16 ][ 아직 남은 공간 ] - 현재 블록의 앞부분 크기를
-
3-2.
bp = NEXT_BLKP(bp);bp를 방금 만든 alloc 블록 다음 블록으로 옮긴다- 즉 이제
bp는 남은 조각의 시작을 가리키게 됨
ex)
[ alloc 16 ][ free 24 ] ^ bp 이동 - 즉 이제
-
3-3. 남은 조각을 새 free block으로 만든다
PUT(HDRP(bp), PACK(csize - asize, 0)); PUT(FTRP(bp), PACK(csize - asize, 0));ex)
[ alloc 16 ][ free 24 ]
#### 4. 분할하지 않는 경우
else { PUT(HDRP(bp), PACK(csize, 1)); PUT(FTRP(bp), PACK(csize, 1)); }- 남는 공간이 너무 작으면 쪼개지 말고, 현재 free block 전체를 통째로 할당
ex)
csize = 24asize = 16- 남는 크기 = 8
- 그런데 8은 최소 블록 크기 16보다 작음
- 그냥 자르지 않고 할당
처음 [ free 24 ] 남는 크기 = 8 < 16 place 후 [ alloc 24 ]